parallel_enable partition by hash |
Below i have tried to illustrate a simple example of using GROUP BY function with PARALLEL_ENABLE TABLE functions in ORACLE.
-- Assume you
create a sample dataset from DBA_OBJECTs and you want to run a simple
sum(obect_id) and count(object_id) group by owner ..
/* now a simple group by result will look like this.
*/


however,
if the data in the table has to be validated through a complex
validation process, then this could take a lot of time when the table is
large.
This is because the validation process done through
procedure or function is a serial process. In order to speed this
process, we can run the validation process in parallel through use of
parallel_enabled table function, but still maintain the ability to group
by column for the end output. This way, you will be able run data
validation process in parallel and at the same time create table
functions capable of doing GROUP BY aggregations.
-- now in my first iteration, I try to do the paralle_enable table function using PARTITION BY ANY, This is the what is most common way to partition data.
the function created to do this is below.
FUNCTION test_group_any( p_cursor IN SYS_REFCURSOR)
RETURN t_owner_summary_tab PIPELINED PARALLEL_ENABLE(
PARTITION p_cursor BY ANY)
IS
in_row data_tab%ROWTYPE;
out_row t_owner_summary_row ;
v_total NUMBER := NULL;
v_owner data_tab.owner%TYPE;
v_count NUMBER := 0;
BEGIN
-- for every transaction
LOOP
FETCH p_cursor
INTO in_row;
EXIT
WHEN p_cursor%NOTFOUND;
-- if we pass the extensive validation check
-- IF super_complex_validation(in_row.object_id,in_row.owner) THEN
RETURN t_owner_summary_tab PIPELINED PARALLEL_ENABLE(
PARTITION p_cursor BY ANY)
IS
in_row data_tab%ROWTYPE;
out_row t_owner_summary_row ;
v_total NUMBER := NULL;
v_owner data_tab.owner%TYPE;
v_count NUMBER := 0;
BEGIN
-- for every transaction
LOOP
FETCH p_cursor
INTO in_row;
EXIT
WHEN p_cursor%NOTFOUND;
-- if we pass the extensive validation check
-- IF super_complex_validation(in_row.object_id,in_row.owner) THEN
-- set initial total or add to current total
-- or return total as required
IF v_total IS NULL THEN
v_total := in_row.object_id;
v_owner := in_row.owner;
v_count := 1;
ELSIF in_row.owner = v_owner THEN
v_total := v_total + in_row.object_id;
v_count := v_count + 1;
ELSE
out_row.owner := v_owner;
out_row.sum_total_id := v_total;
out_row.count_total_id := v_count ;
PIPE ROW(out_row);
v_total := in_row.object_id;
v_owner := in_row.owner;
v_count := 1;
END IF;
-- END IF; -- end super complex validation
-- or return total as required
IF v_total IS NULL THEN
v_total := in_row.object_id;
v_owner := in_row.owner;
v_count := 1;
ELSIF in_row.owner = v_owner THEN
v_total := v_total + in_row.object_id;
v_count := v_count + 1;
ELSE
out_row.owner := v_owner;
out_row.sum_total_id := v_total;
out_row.count_total_id := v_count ;
PIPE ROW(out_row);
v_total := in_row.object_id;
v_owner := in_row.owner;
v_count := 1;
END IF;
-- END IF; -- end super complex validation
END LOOP; -- every transaction
out_row.owner := v_owner;
out_row.sum_total_id := v_total;
out_row.count_total_id :=v_count;
PIPE ROW(out_row);
RETURN ;
END test_group_any;
out_row.owner := v_owner;
out_row.sum_total_id := v_total;
out_row.count_total_id :=v_count;
PIPE ROW(out_row);
RETURN ;
END test_group_any;
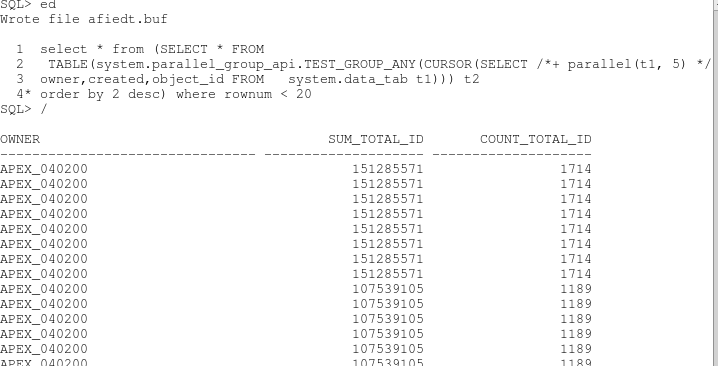
--
the data processed by each parallel process is random and you will get a
lot more rows than expected.. The result is not what we are looking
for.
So what if you partition by hash on owner ?
Note:
in order to PARTITION BY HASH, the database needs to know the
table/object you are passing. so a sys_refcursor will not work. I
changed sys_refcursor to table of %ROWTYPE. from the above function and
changed to PARTITION BY HASH instead of PARTITION by ANY.
FUNCTION test_group_hash( p_cursor IN t_data_tab_ref_cursor)
RETURN t_owner_summary_tab PIPELINED PARALLEL_ENABLE( PARTITION p_cursor BY HASH( owner))
IS

RETURN t_owner_summary_tab PIPELINED PARALLEL_ENABLE( PARTITION p_cursor BY HASH( owner))
IS

-- still not what we want.. the output is almost similar to partition by any ..
-- so now, i added one additional line CLUSTER BY OWNER. This will tell the database to send all rows with the same value for owners to a single parallel slave function.
FUNCTION test_group_hashcluster( p_cursor IN t_data_tab_ref_cursor)
RETURN t_owner_summary_tab PIPELINED PARALLEL_ENABLE( PARTITION p_cursor BY HASH( owner))
RETURN t_owner_summary_tab PIPELINED PARALLEL_ENABLE( PARTITION p_cursor BY HASH( owner))
CLUSTER p_cursor BY( owner)


Hurray. success
now the result is exactly similar to our sql group by function.
however, it took about 27 seconds even with parallel degree 5 in my Virtual machine ..
So i added code to BULK COLLECT in parallel and it runs in less than 2 seconds.
No comments:
Post a Comment
Feedback welcome