

In 11g database,
the more index you have in a table, the longer it takes to insert rows into
that table. When a row is inserted into a table, rowid, and column values are
inserted into the index. Further, if several sessions are concurrently
inserting data, there will be contention to insert data into the same table and
index block. This issue can be further magnified in RAC servers, where these
user sessions will have block contention across different RAC
servers. Some of the solutions to remove these contention is to try to
distribute the data inserted across several blocks by using hash partitions or
reverse key indexing or even in some cases use exchange partition strategy.
While all these methods are
still relevant in
12c as well, it is possible to reduce the index contention completely on some indexes by not having the indexes built during inserts.
This can be done using 12c new
feature called partial index. Note that indexes are used mainly to speed queries
or reports. There may be still some indexes like unique index, indexes on foreign
key column and some additional indexes which might be required to speed look-ups to do the insert into tables. Rest of the indexes which could wait
to be asynchronously built but still report in real time could use
PARTIAL indexing.


To create partial indexes, you have to set INDEXING parameter on the table and then alter or create index with the PARTIAL clause.
To configure indexes to have PARTIAL GLOBAL and PARTIAL LOCAL index on a partitioned
table. There are two places you can set this feature.
1) indexing ON/OFF at table level
2) indexing ON/OFF at the table
partition level.
and then
Alter or create index with partial clause.
e.g. alter index global_idx indexing partial;
create index local_idx on tabname(colname) local indexing PARTIAL;
and then
Alter or create index with partial clause.
e.g. alter index global_idx indexing partial;
create index local_idx on tabname(colname) local indexing PARTIAL;
The parameter set at table level to OFF will set newer default partitions created with indexing OFF at partition level. Indexing ON at table level will set INDEXING ON at partition level for newly created partition. The key to note is "newly created". We will make use of this feature to implement a performance strategy.
The global partial index will have only one index segment. The size of the global partial index will be smaller than a full index as it will not have data of partitions where indexing is OFF.
The local partial index will have index segments on partitions where indexing is ON and no index segments on partitions where it is set OFF. In 11g, it was possible to make some of the index segments unuseable. however, it was not easy to maintain. It would not work with rebuilds and the index segments were created even if they are unusable.
The query optimizer will use global/local partial index where ever available and do partition scan where indexing is OFF to get the full picture. The execution plan will have a UNION-ALL to combine the data from index range scan and partition range scan. The cost of this operation will be higher than full index range scan but lesser than a full table scan.
Below explain plan shows the UNION-ALL to combine partial index data with partition scan.

The global partial index will have only one index segment. The size of the global partial index will be smaller than a full index as it will not have data of partitions where indexing is OFF.
The local partial index will have index segments on partitions where indexing is ON and no index segments on partitions where it is set OFF. In 11g, it was possible to make some of the index segments unuseable. however, it was not easy to maintain. It would not work with rebuilds and the index segments were created even if they are unusable.
The query optimizer will use global/local partial index where ever available and do partition scan where indexing is OFF to get the full picture. The execution plan will have a UNION-ALL to combine the data from index range scan and partition range scan. The cost of this operation will be higher than full index range scan but lesser than a full table scan.
Below explain plan shows the UNION-ALL to combine partial index data with partition scan.

The trade off to use partial index will depend on
- the cost & performance of the queries using partial index
- to the improved speed of OLTP transaction.
It is more favorable to use partial index when
- The oltp transaction rate is critical.
- The performance of queries with partial index is not tht different .
- The resource used to run queries with partial index does not impact the overall performance of the system.
When you ALTER the partition level indexing from OFF to ON, the local index will be created and global index rebuild to add the partition's data.
When you have INTERVAL PARTITION table, Oracle will automatically create the next partition when the data inserted into the table is beyond the current high value of range partition. These partitions will pickup the information from the table level.
At the partition level, INDEXING OFF will mean that the indexes will not be created for that partition.
In order to reduce index contention for application with high inserts, one way is to not have any non-essential indexes on the latest partition where concurrent sessions are inserting data. Having no index on the latest partition will speedup inserts. Reports that do use these indexes will continue to use PARTIAL indexes on older partitions and a Full Table Scan (FTS) on the latest partition.
Steps below describes how to do this.
Steps below describes how to do this.
1) Alter current partitioned table to have indexing OFF at table level. This will ensure that all new partitions added will not automatically enable indexes. ( global and local)
2) If the partition scheme is range partition, you can alter table to have interval partition so that you need not manually add partitions. Although this is a optional step,it is better to have partitions created automatically.
3) create or alter all nonessential indexes with the partial index clause.
4) During inserts into these partitioned tables, newly created partitions will not have partial indexes created. With interval partition, the automatically created partition will not have any partial indexes created. it is the last partition where data is inserted and has usually has the highest contention. Now with less indexes on this partition, the inserts will run a lot faster. At the same time , the reports will still run real time with the latest data inserted. It could be slightly more expensive due to the full scan on the last partition.
5) Have a background job or manually turn INDEXING ON for all partitions where the heavy inserting is not happening. This will automatically rebuild global partial indexed on that table as well as create local partial indexes on that table partition.
That is it. This is one of the strategy you can use to speed OLTP inserts and reduce contention in 12c using PARTIAL INDEXING.
Note: although the example below is using interval range partition, partial indexing will work on other partitions as well.
At the time of writing this blog, there is a documented Bug 14558315 that does a FTS instead of union-all between index scan and partition scan.
1) Create partitioned table. set indexing off at table. You can then set indexing on at partition level.
drop table poc_data purge;
create tablepoc_data (
start_date DATE,
store_id NUMBER,
inventory_id NUMBER,
qty_sold NUMBER
)
INDEXING OFF
PARTITION BY RANGE (start_date)
INTERVAL(NUMTOYMINTERVAL(1, 'MONTH'))
(
PARTITION poc_data_p2 VALUES LESS THAN (TO_DATE('1-7-2007', 'DD-MM-YYYY')) INDEXING on,
PARTITION poc_data_p3 VALUES LESS THAN (TO_DATE('1-8-2007', 'DD-MM-YYYY')) INDEXING on
);
-- create global and local index with PARTIAL clause.
create index global_partial_index on poc_data(store_id) GLOBAL INDEXING PARTIAL;
create index local_partial_index on poc_data(inventory_id) LOCAL INDEXING PARTIAL;
create index local_partial_index on poc_data(inventory_id) LOCAL INDEXING PARTIAL;
2) Load some data to create newer interval partition.
begin
for i in 1..144 loop
for j in 1..10000 loop
insert into poc_data values (TO_DATE('1-8-2007', 'DD-MM-YYYY') +i,i,J,i+j);
end loop;
commit;
end loop;
commit;
end;
/
-- check the partition indexing parameter is off as it is set to off at table level.
SQL> col table_name format a15
SQL> col partition_name format a20
SQL> select table_name, partition_name, indexing from user_tab_partitions where table_name='POC_DATA';
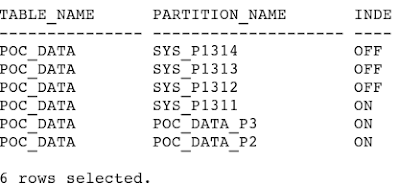
SQL> col partition_name format a20
SQL> select table_name, partition_name, indexing from user_tab_partitions where table_name='POC_DATA';

-- check the local indexes are created to only partitions where indexing ON is set. and obser the leaf_blocks count for PARTIAL global index.
SQL> col index_name format a30
SQL> select index_name, partition_name,segment_created,status,leaf_blocks fromuser_ind_partitions where index_name in (select index_name from user_indexes where table_name='POC_DATA')
union all
select Index_name, 'SINGLE GLOBAL INDEX' PARTITION_NAME,'YES' SEGMENT_CREATED,status, leaf_blocks from user_indexes where table_name='POC_DATA'
and partitioned='NO';
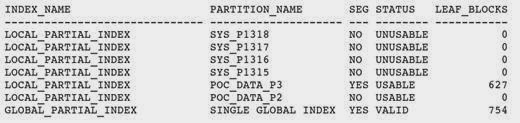
-- Manually enable the partial index on on one of the new partitions..
alter table poc_data modify partition SYS_P1283 indexing on ;
-- this will automatically rebuild global index and create a partial local index on that partition.
-- update statistics to update leaf_block info
begin
dbms_stats.gather_table_stats(ownname=>user, tabname=>'POC_DATA', estimate_percent=>null, cascade=> true);
end;
/
end;
/
-- check the index segments and observer leaf_blocks in global nonpartitioned index has increased.


Conclusion.
Combining 12c
PARTIAL INDEXING feature and
INTERVAL PARTITION , you can easily automate index maintenance that could speed up
performance of OTLP applications.

.png)

